Currently, machine learning systems are at the core of many AI-powered applications and services. Thanks to these systems, the tools we use to train AI models can generate results based on the patterns they identify in the data we provide. Ideally, a good model should perform well not only on the data it was trained with but also on entirely new data. This ability to “generalise” is what makes machine learning valuable in real-world settings.
However, in practice, models often behave differently when faced with unfamiliar data. They usually deliver higher confidence scores on their training data compared to new inputs. This uneven performance forms the basis for a privacy risk known as a membership inference attack.
How Membership Inference Attacks Work
The main purpose of a membership inference attack (MIA) is to determine whether specific data was part of a model’s training dataset. If successful, it can expose sensitive or personal information, especially when the model has been trained on private records, such as medical or financial information.
What’s especially concerning is that attackers don’t need access to the model’s dataset, weights, biases, or internal architecture. Often, simply knowing the type of model— for example, whether a neural network or decision tree-based model was used—or the platform it was built on is enough to carry out an MIA.
The rise of machine learning-as-a-service (MaaS) platforms, like Google’s Vertex AI and Amazon SageMaker, has made these attacks even more feasible. Such platforms allow developers to train sophisticated models quickly and easily without needing to handle technical complexities. However, the same tools that make development easier also give attackers the means to replicate model configurations and launch inference attacks.
To gain a clearer understanding of how machine learning works in a real-world setting and how MIAs take place, let’s consider a hypothetical scenario based on a well-known example often used in introductory machine learning courses: the Iris flower dataset. What follows is a thought experiment designed purely to illustrate the core concepts.
1. Suppose we had a dataset containing the measurements of sepal length and width along with petal length and width for three species of iris flowers: Iris setosa, Iris versicolor, and Iris virginica.

2. In this scenario, each data point would be labelled with the correct species based on the recorded measurements.
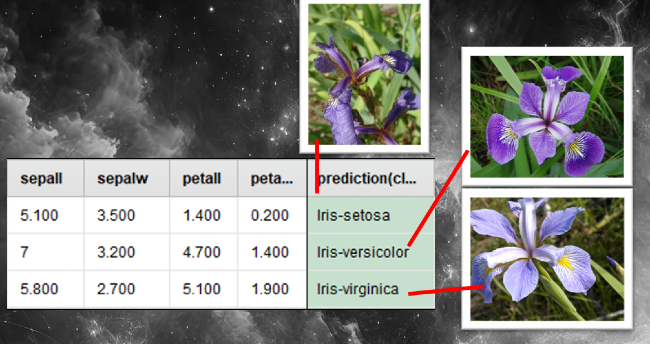
3. We could then use this labelled dataset to train a classification model, enabling it to learn how those measurements correspond to each type of iris flower.
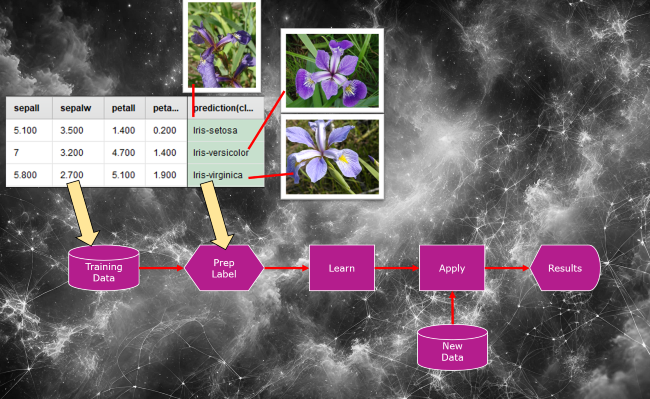
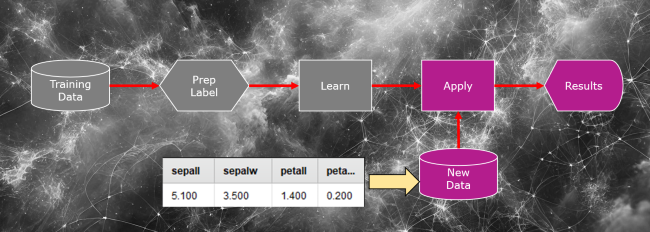
4. After training, we might feed the model new data (just petal and sepal measurements)
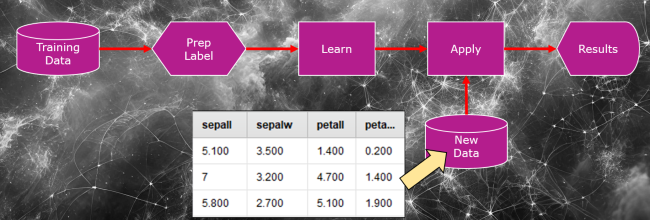
5. The model would then process the new input and generate probabilities, indicating the most likely type of iris flower.
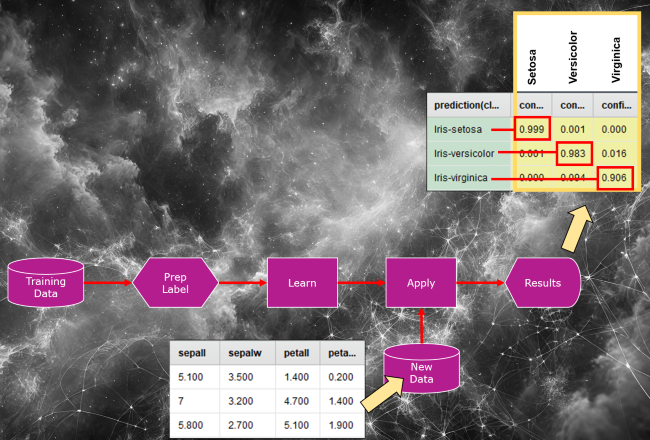
Using this hypothetical model setup, we can demonstrate the steps taken to carry out an MIA and potentially uncover training data:
1. Let’s say we submit new flower measurements (sepal and petal width and length) to the model.
2. In this case, the model would be expected to return a prediction, complete with confidence (probability) scores (see the image below).
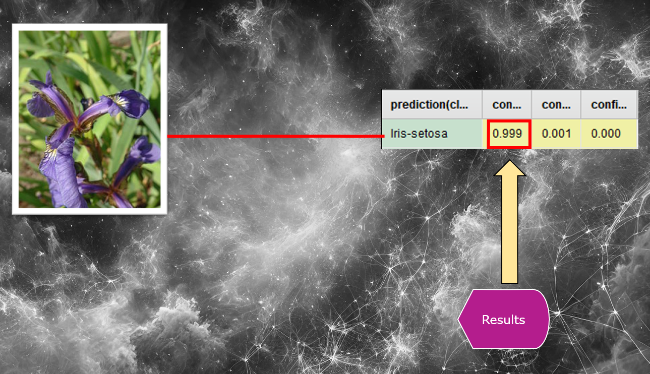
While our example is a purely conceptual demonstration and not a record of an actual implementation, the image above shows that when training data is mixed with new data and run through the neural network again, the model might produce higher confidence scores for the data it has encountered during training.
In actual scenarios, attackers can exploit this behaviour by subtly adjusting their input and repeating the process until the model returns higher confidence scores. By observing how confidently the model responds to different inputs, they can determine whether a particular data point was part of the training set.
Once enough of these high-confidence scores are gathered, attackers can build shadow models, which are replicas that mimic the behaviour of the original model. These shadow models are then used to train a final inference model, which can predict whether any given data point was part of the original training dataset.
How Dangerous Are Membership Inference Attacks?
MIAs pose a serious privacy risk, especially for AI systems trained on sensitive data, such as medical records, biometric details, financial information, or personal user data. If attackers can determine that a model was trained on personal information, they may be able to gather sensitive details— such as medical diagnoses or financial statuses—without needing access to the original dataset.
Not only does this type of vulnerability violate individual privacy, but it can also breach data protection laws, erode user trust, and create reputational or legal consequences for the organisation responsible for the model.
Why Some Models Are More Vulnerable Than Others
Using model outputs, such as confidence scores or prediction probabilities, to infer training data has proven to be an effective MIA technique across various machine learning services and model types. However, inference models can sometimes assign high-confidence scores to data not present in the original training set, leading to false positives. This overlap between confident predictions on unseen data and actual training data blurs the line between legitimate generalisation and genuine vulnerability.
That said, not all machine learning systems are equally exposed. MIAs tend to be more viable when models are trained on structured, low-dimensional data—such as spreadsheets containing medical records or financial transactions—as these are easier to reconstruct or simulate. In contrast, models trained on complex image datasets or large multi-class datasets are harder to breach due to the difficulty of crafting convincing fake examples.
Overfitting is another major factor that contributes to the success of MIAs. It typically occurs when a model is trained on too few samples or for too long, causing it to become overly tailored to its training data and, thus less effective on new, unseen inputs.
Overfitted models are particularly vulnerable because they tend to respond more strongly to the data on which they were trained. This “exaggerated” confidence is exactly the type of behaviour attackers try to exploit. On the other hand, models that “generalise” well, meaning they perform consistently across both familiar and novel data, tend to be more resistant to MIAs.
MIAs pose a real threat to privacy, particularly in fields that deal with sensitive data. To protect against such attacks, developers must strike a careful balance between model accuracy and generalisation, not only to improve model robustness and performance but also to safeguard the data on which their systems rely. Other mitigation strategies include applying differential privacy, limiting the granularity of model outputs, and using regularisation techniques to reduce overfitting.
Related Content
In the following video, we will use the Iris Flower Classifier to further explore the pitfalls of algorithmic decision making.



